I. Overview
As the most natural form of human-computer interaction, voice, is changing people's lives and enriching multimedia applications. Speech recognition technology is an important branch of speech signal processing, and it is also a research field that has been very popular in recent years. With the rapid development of science and technology, speech recognition has been widely used not only in desktop PCs and large workstations, but also in the field of embedded systems, such as smart home, voice assistant, car voice recognition system. I believe in the near future, speech recognition technology will inevitably penetrate every corner of people's lives.
Second, the classification of speech recognition system
Speech recognition can be divided into isolated word recognition, connected word recognition, and continuous speech recognition in accordance with the speaker's way of speaking. Isolated word recognition means that the speaker speaks only one word or phrase at a time. Each word or phrase is counted as a term in the vocabulary. It is generally used in voice dialing systems. The conjunction speech recognition supports a small syntax. The network, which forms a state machine inside, can realize simple control of household appliances, while the complex connection word voice recognition system can be used in systems such as telephone voice inquiry and airline reservation; continuous speech recognition refers to the daily nature of speakers. The pronunciation of the way, usually refers to the dictation machine for voice input.
From the point of view of the type of recognition object, speech recognition can be divided into Speaker Dependent speech recognition and Speaker Independent speech recognition. A specific person refers to speech recognition for only one user, while a non-specific person can use for different users.
The size of the vocabulary identified can be divided into small vocabulary (less than 100 words), medium vocabulary (100 to 500 words), and large vocabulary (more than 500 words).
Non-specific NPC vocabulary continuous speech recognition is the focus of research in recent years, but also difficult to study. Most of the current continuous speech recognition is based on the HMM (Hidden Markov Model) framework, and the introduction of acoustics and linguistic knowledge has been introduced to improve this framework. Its hardware platform is usually a powerful workstation or PC.
Third, the principle of speech recognition
Speech recognition analyzes and understands the voice signal input by the microphone and converts it into the corresponding text or command.
A complete speech recognition system mainly consists of three parts:
Voice Feature Extraction (Front-End Processing Section): The purpose is to filter out various interference components and extract feature vector sequences that can represent voice content as a function of time from the speech waveform.
Acoustic models and pattern matching (recognition algorithms): Acoustic models are usually generated from the acquired speech features through training in order to create a pronunciation template for each pronunciation. In the recognition, the input speech features are matched and compared with the acoustic model to obtain the best recognition result.
Semantic comprehension (post-processing): The computer performs semantic and grammatical analysis of the recognition results and understands the meaning of the speech in order to make a corresponding response, usually through a language model.
The principle of voice recognition is shown below:
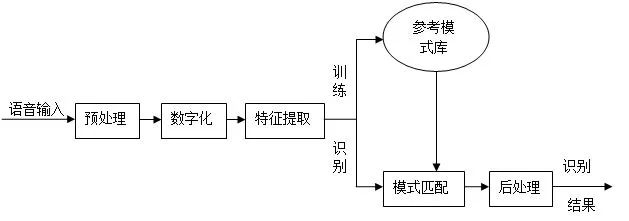
The speech to be recognized is converted into an electrical signal by the microphone and then added to the input of the recognition system. After preprocessing, speech feature extraction is performed, and several parameters reflecting the characteristics of the speech signal are used to represent the original speech. Commonly used speech features include: Linear Prediction Coefficient (LPC), Linear Prediction Cepstrum Coefficient (LPCC), Mel Spectrum Coefficient (MFCC), and the like.
It is divided into two phases: training phase and identification phase.
In the training phase, the speech signals expressed in the form of characteristic parameters are processed correspondingly, standard data representing the common features of the recognition basic units are obtained, thereby constituting a reference template, and all the reference templates of the recognizable basic units are combined together to form a reference. Pattern library
In the recognition stage, the speech signals to be identified are subjected to feature extraction and matched with each template in the reference pattern library one by one according to a certain principle to find out the pronunciation corresponding to the most similar reference template, namely, the recognition result.
Finally, speech processing involves grammar analysis, speech understanding, semantic network, and so on.
The speech recognition process should calculate the distance measure between the unknown speech mode and each template in the speech template library according to the pattern matching principle, so as to obtain the best matching pattern. The pattern matching methods applied in speech recognition include Dynamic Time Warping (DTW), Hidden Markov Model (HMM) and Artificial Neural Networks (ANN).
Fourth, the problem
Recognition rate is an important indicator to measure the performance of speech recognition systems. In practical applications, the recognition rate is mainly affected by the following factors:
For Chinese speech recognition, dialect or accent will reduce the recognition rate;
Background noise. The strong noise in public places has a great impact on the recognition effect. Even in the laboratory environment, tapping the keyboard or moving the microphone will become background noise.
The "spoken language" problem. It involves both natural language understanding and acoustics. The ultimate goal of speech recognition technology is to allow users to be as natural as “people-to-people dialogues†in “human-computer conversations,†and the grammatical patterns of spoken English are not regulated as soon as users engage in speech input in a manner that speaks to people. The abnormality of word order can bring difficulties to the analysis and understanding of semantics.
In addition, the recognition rate is also related to the speaker's gender, length of speech, and so on.
Real-time performance is another measure of the performance of speech recognition systems. For a PC with a high-speed computing capability and a large-capacity memory, it can basically meet the requirements of real-time performance; and for an embedded system with limited resources, the real-time performance can hardly be guaranteed.
Fume Ultra Vape,Fume Ultra Disposable Vape,Fume Ultra Disposable 2500 Puffs,Fume Ultra 2500Puffs Vape
Nanning Nuoxin Technology Co., LTD , https://www.nx-vapes.com