
abstract
The deep-learning textbook, Deep Learning, which was founded by world-famous experts Ian Goodfellow, Yoshua Bengio, and Aaron Courville, was the first of its kind. The contents of the book include three parts: First, introduce the basic mathematical tools and machine learning concepts, which are the preliminary knowledge of deep learning; Second, systematically explain in depth today's mature deep learning methods and techniques; Third, discuss some with forward-looking The direction and ideas of sex, they are recognized as the focus of deep learning in the future.
About the Author
[USA] Ian Goodfellow, research scientist at Google, and doctor of machine learning at the University of Montreal in 2014. His research interests cover most of the topics of deep learning, particularly the generation model and the security and privacy of machine learning. Ian Goodfellow was an influential early researcher in the study of confrontational samples. He invented the generative confrontation network and made outstanding contributions in the field of deep learning.
[Add] Yoshua Bengio, Professor of the Department of Computer Science and Operations Research (DIRO), University of Montreal, Director of the Montreal Institute of Learning Algorithms (MILA), Co-Head of the CIFAR Project, Chair of Statistics Research Algorithm Research in Canada . Its main research goal is to further understand the learning principles that generate intelligence.
[Add] Aaron Courville, assistant professor of the Department of Computer Science and Operations Research at the University of Montreal, and a member of the LISA laboratory, whose research interests are mainly focused on the development of deep learning models and methods, especially the development of probability models and novel inferences. Methodologically. In addition, he also focuses on computer vision applications and has also studied other fields such as natural language processing, audio signal processing, speech understanding, and other AI-related tasks.
Book information
Title: Deep Learning
Book number: 978-7-115-46147-6
Author: [US] Ian Goodfellow (Ian Goodfellow), [plus] Yoshua Bengio (Joshua Ben GIO), [plus] Aaron Courville (Aaron Courville)
Translator: Zhao Shenjian, Li Yujun, Fu Tianfan, Li Kai
Reviewer: Zhang Zhihua
Publication Date: August 2017
Pricing: 168 yuan
For more information, please visit People's Posts and Telecommunications Press Asynchronous Community:
Readable people
"Deep Learning" is suitable for all types of readers, including undergraduates or postgraduates of related majors, and software engineers who do not have machine learning or statistical backgrounds but want to quickly supplement deep learning knowledge for use in real products or platforms.
Recommended reason
AI Bible! Foundational classic bestseller in the field of deep learning!
Long-term ranked first in the United States Amazon AI and machine learning books!
The must-read book for all data scientists and machine learning practitioners!
Tesla CEO Elon Musk and many other domestic and foreign experts recommend!
Experts recommend
1. "Deep learning" was written by three experts in the field and is currently the only comprehensive book in the field. It provides a wide range of perspectives and basic mathematics knowledge for software engineers and students who are entering the field, and can also provide reference for researchers.
牎狾penAI co-chair, Tesla and SpaceX co-founder and CEO Elon Musk
2. This is an authoritative textbook for deep learning, written by major contributors in the field. This book is very clear, comprehensive and authoritative. Reading this book, you can understand the origin of deep learning, its benefits, and its future.
—Geoffrey Hinton, Distinguished Research Scientist, University of Toronto, Honorary Retirement Professor
3. In the past decade, deep learning has become a popular technology. Students, practitioners and teachers all need such a textbook containing basic concepts, practical methods and advanced research topics. This is the first comprehensive textbook in the field of deep learning, written by several of the most creative and prolific researchers. This book will become a classic.
- Dean of the Facebook Artificial Intelligence Institute Yann LeCun, professor of computer science, data science and neuroscience at New York University
4. In-depth learning has achieved great success in both academia and industry in recent years, but as the author of this book has said, deep learning is an important method for creating artificial intelligence systems, but not all methods. The researchers who are expected to make a difference in the field of artificial intelligence can fully consider the connection and difference between deep learning and traditional machine learning and artificial intelligence algorithms through this book, and jointly advance the development of this field.
— Dr. Hua Gang, Principal Research Fellow, Microsoft Research
5. This is a deep learning textbook that is still being developed, researched, and engineered at the writing stage. Its publication shows that we have entered a new era of systematic understanding and organization of deep learning frameworks. This book introduces the basic mathematics, machine learning experience, and the theory and development of deep learning at this stage. It can help AI technology enthusiasts and practitioners to understand deep learning in all directions under the guidance of three experts and scholars.
— Tencent Outstanding Scientist and Professor of the Chinese University of Hong Kong Jia Jiaya
6. Deep learning represents the artificial intelligence technology of our time. This book written by Good-fellow, Bengio, and Courville, the most authoritative scholars in the field, is entitled “Deep Learningâ€. It covers the basic techniques and applications of deep learning, theory and practice, and other major technologies. Explained profoundly, explained in detail, enriched content. I believe this is a must-read item and a must-have book for everyone concerned with deep learning. Thanks to Prof. Zhang Zhihua's hard-working revisers, this masterpiece can meet Chinese readers so quickly.
牎î€î€¤ æ¬ æ¬ æ¬ 20 20 20 20 20 20 20 20 20
7. From the basic feedforward neural network to the deep generation model, from the mathematical model to the best practice, this book covers all aspects of deep learning. Deep Learning is the most suitable entry book for the moment and is highly recommended to researchers and practitioners in this field.
—Li Mu, the chief scientist of Amazon and one of the initiators of Apache MXNet
8. Textbooks from the top three authoritative scholars of deep learning must put a book before the case. The second part of the book is the essence of profound learning.
- One of the ResNet authors, Face++ chief scientist Sun Jian
9. In the past decade, the widespread application of deep learning has created a new era of artificial intelligence. This textbook is written jointly by several academics who have significant influence in the field of deep learning. It covers the main directions of deep learning and provides a good systematic teaching material for researchers, engineers and beginners who want to enter the field.
- Prof. Tang Xiaoou, Director of Information Engineering Department, The Chinese University of Hong Kong
10. This is a textbook and it is not just a textbook. For any reader interested in deep learning, this book will be the most comprehensive and systematic data you can obtain for a long period of time. It is also an excellent theory for thinking about and truly promoting the application of deep learning industry and building an intelligent social framework. starting point.
— Xin Zhiyuan Founder and CEO Yang Jing
Translator's preface
Castle Peak can not cover, after all, go east
Since the term “deep learning†was formally proposed in 2006, it has grown tremendously in the last 10 years. It has revolutionized Artificial Intelligence (AI), allowing us to truly appreciate the potential of artificial intelligence to bring change to human life. In December 2016, MIT Press published the book “Deep Learning†by Ian Goodfellow, Yoshua Bengio, and Aaron Courville. The three authors have been cultivating the frontiers of machine learning, leading the development of deep learning, and are major contributors to many methods of deep learning. The book became popular around the world as soon as it was published.
This is a textbook that covers the details of deep learning technology. It tells us that deep learning is a combination of technology, science, and art. It involves statistics, optimization, matrix, algorithms, programming, distributed computing, and other fields. The book also contains the author's understanding of deep learning and thinking, everywhere with deep thoughts, incomparable. The first chapter's discussion on deep learning and historical development is particularly thorough and insightful.
The author wrote in the book: "The real challenge of artificial intelligence is to solve tasks that are easy for humans to implement but that are difficult to formalize, such as identifying what people are saying or the faces in images. For these questions, we Humans can often be resolved easily with intuition." In response to these challenges, they proposed that computers learn from experience and understand the world based on a hierarchical conceptual system, and each concept is defined by the relationship with some relatively simple concepts. Thus, the author gives the definition of deep learning: “The concept of hierarchy allows computers to construct simpler concepts to learn complex concepts. If we draw a diagram that shows how these concepts are built on each other, we will get a A picture of "deep" (many levels). Thus, we call this method AI deep learning (deep learning).
The authors pointed out: "Generally speaking, deep learning has gone through three waves of development so far: the embryonic form of deep learning in the 1940s to the 1960s appeared in cybernetics, and deep learning in the 1980s and 1990s connected them. Is represented by connectionism, and since 2006, it has revived in the name of deep learning."
Referring to the relationship between deep learning and brain science or neuroscience, the author emphasizes: “Now the role of neuroscience in deep learning research is weakened. The main reason is that we don’t have enough information about the brain to use it as a guide. To gain a deep understanding of the actual use of algorithms in the brain, we need to be able to monitor (at least) the activity of thousands of connected neurons at the same time. We cannot do this, so even the simplest and most in-depth parts of our brain are Still far from understanding." It is worth noting that some experts in China are keen to promote cross-study between artificial intelligence and brain science or cognitive science, and promote the country to invest a lot of resources in the so-called "brain-like intelligence" areas. Regardless of whether or not our country truly has scholars who are versed in artificial intelligence and brain science or cognitive psychology at the same time, at least we must be pragmatic and rational in seeking the right attitude. Only in this way can we make a difference in this wave of artificial intelligence development, instead of becoming a group of wavers.
The author further pointed out: "Media reports often emphasize the similarity of deep learning with the brain. Indeed, deep learning researchers are more likely than other researchers in machine learning areas (such as nuclear methods or Bayesian statistics) to refer to the brain as a reference, but Everyone should not think that deep learning is trying to simulate the brain.Modern deep learning draws inspiration from many fields, especially the basic content of applied mathematics such as linear algebra, probability theory, information theory, and numerical optimization.Although some deep learning researchers cite neuroscience as An important source of inspiration, yet other scholars are completely unconcerned about neuroscience." Indeed, for the majority of young scholars and front-line engineers, we can completely ignore the depth of learning and artificial intelligence because we do not understand neural (or brain) science. Mathematical models, calculation methods and application drivers are the feasible ways we can study artificial intelligence. Deep learning and artificial intelligence are not the frames that hang over our heads, but the techniques that are based on our feet. We can certainly appreciate science and technology from a philosophical point of view, but excessively studying scientific issues from the philosophical level will only lead to some empty nouns.
With regard to the decline of artificial neural networks in the mid-1990s, the authors analyzed: “Startup companies based on neural networks and other AI technologies are beginning to seek investment, and their approach is ambitious but impractical. When AI research cannot achieve these unreasonable At the same time, investors were disappointed with expectations, and at the same time, other areas of machine learning have made progress.For example, both nuclear and graph models have achieved very good results in many important tasks.These two factors have led to the rise of neural networks. The second recession continued until 2007." "Their prosperity is also embarrassing. This lesson is also worthy of the wake-up call of today's entrepreneurial, industrial, and academic circles based on deep learning.
I am very honored to be invited by Mr. Wang Fengsong of the People's Post and Telecommunications Press to take charge of the Chinese translation of the book. I received an invitation from Mr. Wang in July 2016, but at that time I was busy looking for a job and I had no time to attend. However, when I discussed translation issues with my students, they agreed that this was a very meaningful event and expressed willingness to take on it. The translation was independently completed by my four students, Zhao Shenjian, Li Yujun, Fu Tianfan, and Li Kai. Shen Jianhe Tianfan is a second-year master student, while Li Kaihe and Yu Jun are second- and third-grade Zhibo students. Although they are still new in the field of machine learning, their knowledge structure is not comprehensive, but their enthusiasm, diligence in learning, work focus, and execution are extremely strong. They enhanced the understanding by reproducing the algorithm code in the book and reading related documents. They took the first draft of the translation in less than three months, and then tried to make the translation correct through self-proof and cross-checking. Sex and consistency. They are self-coordinating, taking responsibility, and humility. Their sense of responsibility and ability to work independently have made me very gratified and have been able to calmly.
Due to our limited ability in both Chinese and English, the translation may be somewhat blunt. We are particularly concerned about the failure to fully convey the original author's true thoughts and opinions. Therefore, we strongly recommend that qualified readers read the original English text, and we are also very much looking forward to correcting and correcting them in order to further revise and improve them. I urge you to give more than 4 translators for encouragement. Please leave me your critique of translation. This is what I, as their mentor, must bear, and also my commitment to Mr. Wang Fengsong's trust.
When the original translation was basically completed, we decided to publish it on GitHub. We hope to improve the translation through the participation of readers. Surprisingly, there are hundreds of enthusiastic readers who have given a lot of constructive suggestions for revision. Among them, more than 20 enthusiastic readers directly help with the proofreading (see the list of thanks for the Chinese version). It can be said that this translation is the result of our joint efforts. These readers came from first-line engineers and students in school, from which I experienced their love of deep learning and machine learning. More importantly, I feel the spirit of their openness, cooperation, and dedication, which is also indispensable for the development of artificial intelligence. Therefore, I firmly believe that the hope for the development of artificial intelligence in China lies in young scholars. Only they can make our country's artificial intelligence disciplines competitive and influential in the world.
Jiangshan has talented people on behalf of each and every leader for decades!
Zhang Zhihua Ghostwriting
May 12th, 2017 in Beijing University
Highlights first look
Far in the ancient Greek period, inventors dreamed of creating machines that could think independently. The mythological figures Pygmalion, Daedalus and Hephaestus can be regarded as legendary inventors, while Galatea, Talos and Pandora (Pandora) can be regarded as artificial life? Ovid and 燤artin, 2004; Sparkes, 1996; Tandy, 1997).
When humans first conceived of programmable computers, they were already thinking about whether computers could become smart (although this was more than a hundred years before the first computer was created) (Lovelace, 1842). Today, artificial intelligence (AI) has become a field with many practical applications and active research topics, and it is booming. We expect intelligent software to automatically handle routine labor, understand speech or images, aid in medical diagnosis, and support basic scientific research.
In the early days of artificial intelligence, problems that were very difficult for human intelligence but relatively simple for computers were quickly solved, such as those that could be described by a series of formal mathematical rules. The real challenge of artificial intelligence is to solve tasks that are easy for humans to implement, but difficult to formalize, such as recognizing what people are saying or the faces in an image. For these problems, we humans can often easily resolve with intuition.
For these more intuitive issues, Daniel has found a solution. The program allows the computer to learn from experience and understand the world based on a hierarchical conceptual system, and each concept is defined by the relationship with some relatively simple concepts. Getting the computer to gain knowledge from experience can prevent humans from formalizing the computer with all the knowledge it needs. Hierarchical concepts let computers build simpler concepts to learn complex concepts. If we draw a graph that shows how these concepts are built on top of each other, we will get a "deep" (lot of levels) map. For this reason, we call this method AI deep learning.
Many of AI's early successes occurred in a relatively simple and formal environment, and did not require computers to have much knowledge of the world. For example, IBM's Deep Blue chess system defeated world champion Garry Kasparov in 1997 (Hsu, 2002). Obviously chess is a very simple field because it contains only 64 positions and can only move 32 stones in a strictly limited manner. The design of a successful chess strategy is a huge achievement, but describing the pieces to the computer and the methods they allow are not the challenge of this challenge. Chess can be completely described by a very short, fully formalized list of rules, and can be easily prepared by the programmer.
Ironically, abstract and formal tasks are one of the most difficult mental tasks for humans, but they are the easiest for computers. Computers have long been able to defeat the best human chess players, but until recently the computer reached the human average in identifying objects or voice tasks. A person's daily life needs a lot of knowledge about the world. Many of this knowledge is subjective and intuitive, so it is difficult to express clearly in a formal way. Computers need to acquire the same knowledge to show intelligence. One of the key challenges of artificial intelligence is how to communicate these informal knowledge to computers.
Some AI projects seek to hard-code formal knowledge of the world's knowledge. Computers can use logical inference rules to automatically understand the statements in these formal languages. This is the well-known knowledge base method of artificial intelligence. However, these projects did not ultimately achieve major success. One of the most famous projects is Cyc (Lenat and Guha, 1989). Cyc includes an inference engine and a declaration database using the CycL language description. These declarations were entered by human supervisors. This is a clumsy process. People try to design enough formal rules to describe the world accurately. For example, Cyc can't understand a story about a person named Fred shaving in the morning (Linde, 1992). Its inference engine detects inconsistencies in the story: it knows that the body's composition does not contain electrical parts, but since Fred is holding an electric shaver, it considers the entity - "FredWhileShaving" ) Contains electrical components. Therefore, it raises the question of whether Fred is still alone when shaving.
The difficulty faced by relying on hard-coded knowledge systems shows that the AI ​​system needs to have its own ability to acquire knowledge, ie the ability to extract patterns from the original data. This ability is called machine learning. The introduction of machine learning enables computers to solve problems involving real-world knowledge and make seemingly subjective decisions. For example, a simple machine learning algorithm called logistic regression can decide whether to recommend caesarean section (Mor-Yosef爀t al., 1990). Naive Bayes, which is also a simple machine learning algorithm, can distinguish between spam emails and legitimate emails.
The performance of these simple machine learning algorithms depends to a large extent on the representation of the given data. For example, when logistic regression is used to determine whether a woman is suitable for caesarean section, the AI ​​system does not directly examine the patient. Instead, doctors need to tell the system about several related information, such as the presence or absence of uterine scars. Each piece of information that represents a patient is called a feature. Logistic regression learns how these characteristics of the patient are related to various outcomes. However, it does not affect the way this feature is defined. If the patient's MRI (magnetic resonance) scan is used as a logistic regression input instead of a doctor's official report, it will not be able to make useful predictions. The correlation between the single pixel of the MRI scan and the complications during childbirth is negligible.
Reliance on representation is a universal phenomenon throughout computer science and even in everyday life. In computer science, if data collections are finely structured and intelligently indexed, the processing speed of operations such as search can be exponentially accelerated. People can easily perform arithmetic operations under the representation of Arabic numerals, but under the representation of Roman numerals, operations can be time consuming. Therefore, it is not surprising that the choice of representation has a huge impact on the performance of machine learning algorithms. Figure 1 shows a simple visualization example.
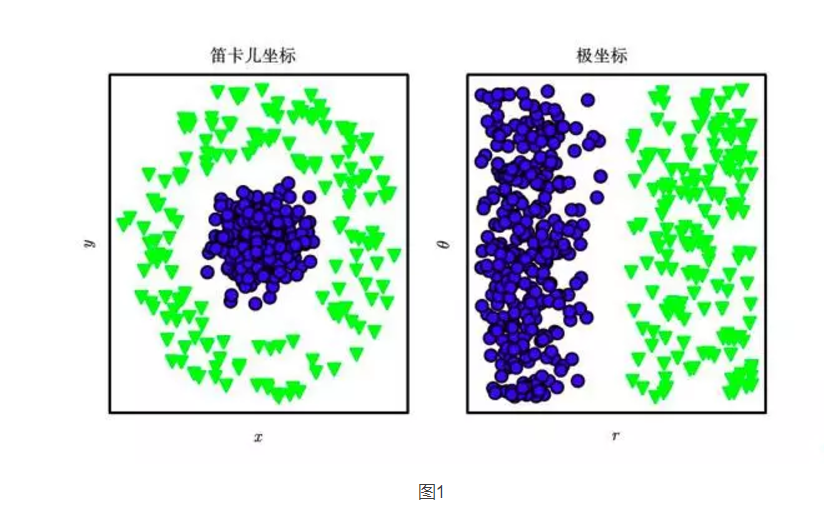
Figure 1 shows an example of different representations: Suppose we want to draw a line in a scatter plot to separate two types of data. In the figure on the left, we use Cartesian coordinates to represent the data. This task is impossible. In the image on the right, we represent the data in polar coordinates. We can simply solve this task with vertical lines (drawing this diagram in collaboration with David Warde-Farley). Many artificial intelligence tasks can be solved by first extracting a suitable feature set. , and then provide these features to a simple machine learning algorithm. For example, one useful feature for the task of discriminating a speaker by sound is the estimation of its channel size. This feature provides strong clues as to whether the speaker is a man, a woman, or a child.
However, for many tasks, it is difficult to know which features should be extracted. For example, suppose we want to write a program to detect the car in the photo. We know that cars have wheels, so we may want to use the presence or absence of wheels as a feature. Unfortunately, it is difficult to accurately describe what the wheel looks like based on pixel values. Although the wheel has a simple geometric shape, its image may vary from scene to scene, such as shadows on the wheels, metal parts of the sun-illuminated wheels, fenders in the car, or foreground objects that are part of the blocked wheel. .
One way to solve this problem is to use machine learning to discover the representation itself, not just map the representation to the output.
This method is called representation learning. Learning representations often perform better than manually designed representations. And with minimal human intervention, they can quickly adapt AI systems to new tasks. It means that the learning algorithm can find a good feature set for simple tasks in just a few minutes, and it takes hours to months for complex tasks. Manually designing features for a complex task requires a lot of manpower, time, and effort, and it may even take decades for the entire community of researchers.
A typical example of a learning algorithm is an autoencoder. The self-encoder consists of an encoder function and a decoder function. The encoder function converts the input data into a different representation, and the decoder function converts this new representation back to the original form. We expect to retain as much information as possible after the input data passes through the encoder and decoder, and at the same time hope that the new representation has a variety of good features, which is also the training goal of the self-encoder. In order to achieve different characteristics, we can design different forms of self-encoders.
When designing features or designing algorithms for learning features, our goal is usually to isolate factors that can explain the observed data. In this context, the word "factor" refers only to different sources of influence; factors are usually not multiplicative combinations. These factors are usually quantities that cannot be directly observed. Instead, they may be unobservable or unobservable forces in the real world, but they can affect the amount of observation. In order to provide a useful simplified explanation of the observed data or to infer its causes, they may also exist in the human mind in the form of concepts. They can be seen as concepts or abstractions of data, helping us understand the richness and variety of these data. When analyzing voice recordings, the factors of variation include the speaker's age, gender, their accent, and what they are saying. When analyzing an image of a car, the deterioration factors include the position of the car, its color, the angle and brightness of the sun.
In many real-world applications of artificial intelligence, the difficulty arises mainly from multiple variability factors that affect every single piece of data we can observe. For example, in a picture containing a red car, its individual pixels may be very close to black at night. The shape of the car's profile depends on the viewing angle. Most applications require us to clarify the factors of variation and ignore the factors that we do not care about.
Obviously, it is very difficult to extract such high-level, abstract features from the original data. Many variability factors such as speaking accents can only be identified through complex, human-level understanding of the data. This is almost as difficult as obtaining the original question. Therefore, at first glance, it seems that learning does not seem to help us.
Deep learning expresses complex expressions through other simpler representations and solves the core problems in representational learning.
Deep learning allows computers to build complex concepts with simpler concepts. Figure 2 shows how deep learning systems represent the concept of people in an image by combining simpler concepts such as corners and outlines, which in turn are defined by edges. A typical example of a deep learning model is a feed-forward depth network or a multi-layer perceptron (MLP). A multi-layer perceptron is simply a mathematical function that maps a set of input values ​​to output values. This function is compounded by many simpler functions. We can think of each application of different mathematical functions as providing a new representation of input. The idea of ​​learning the correct representation of data is a perspective to explain deep learning. Another perspective is the depth of computer learning to a multi-step computer program. Each layer representation can be thought of as the memory state of the computer after executing another set of instructions in parallel. Deeper networks can execute more instructions in sequence. Sequential instructions provide a great deal of power because later instructions can refer to the results of earlier instructions. From this perspective, not all information in a certain level of activation function imply changes in interpretation input. The status information is also stored to help the program understand the input. The status information here is similar to a counter or pointer in a conventional computer program. It has nothing to do with the specific input, but it helps the model organize its processing.
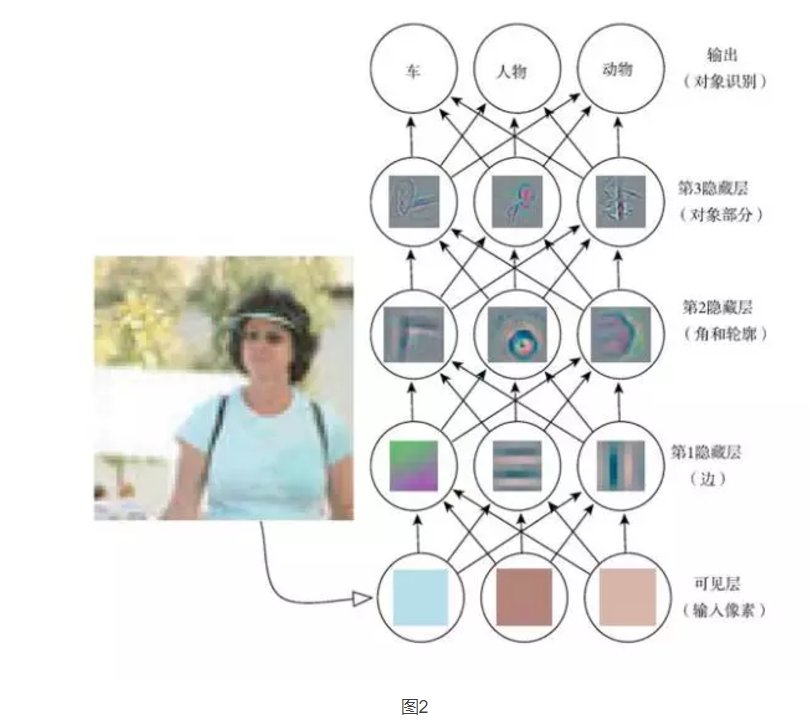
Figure 2 Schematic diagram of the deep learning model. It is difficult for a computer to understand the meaning of raw sensory input data, such as an image represented as a set of pixel values. The function of mapping a set of pixels to the object ID is very complicated. If you work directly, learning or evaluating this map seems impossible. Deep learning solves this problem by decomposing the required complex map into a series of nested simple maps (each described by different layers of the model). The input is shown on the visible layer. The reason for this name is because it contains variables that we can observe. Then there is a series of hidden layers that extract more and more abstract features from the image. Because their values ​​are not given in the data, these layers are called "hidden layers"; the model must determine which concepts are conducive to interpreting the relationships in the observation data. The image here is a visualization of the features represented by each hidden unit. For a given pixel, Layer 1 can easily identify edges by comparing the brightness of adjacent pixels. With the edges described by the first hidden layer, the second hidden layer can easily search for edge sets that can be identified as corners and extended outlines. Given the image description of angles and contours in the second hidden layer, the third hidden layer can find a specific set of contours and corners to detect the entire part of a particular object. Finally, according to the part of the object contained in the image description, the objects existing in the image can be identified (referenced by permission of Zeiler and Fergus (2014)). At present, there are mainly two ways of measuring the depth of the model. One way is based on evaluating the number of sequential instructions that the architecture needs to perform. Assuming that we represent the model as a given input and then calculate the corresponding output flow chart, we can treat the longest path in this flow chart as the depth of the model. Just as two equivalent programs written in different languages ​​will have different lengths, the same function can be drawn as a flowchart with different depths, the depth of which depends on the functions that we can use as a step. The maps are difficult to find out why they are difficult to pick up stomachs, reefs, and reefs.
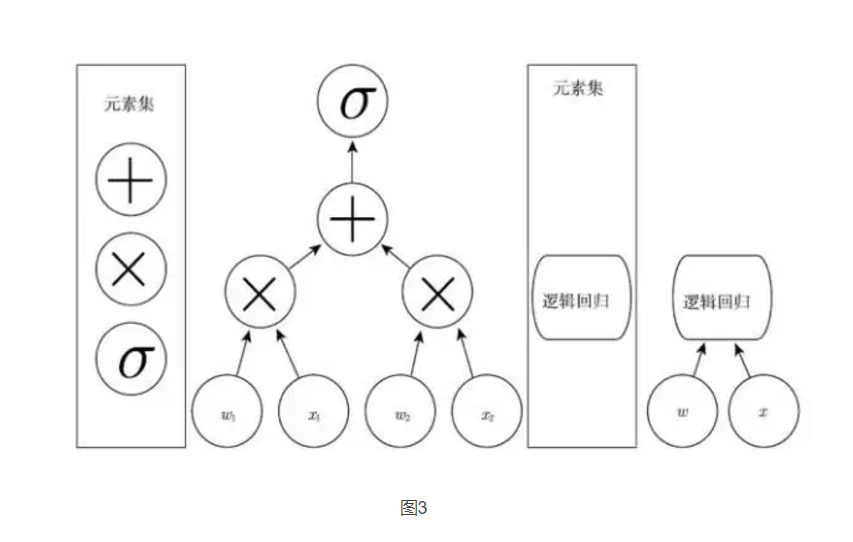
Figure 3 Schematic diagram of the calculation graph that maps the input to the output, where each node performs one operation. Depth is the length of the longest path from input to output, but it depends on the definition of possible calculation steps. The calculations shown in these figures are the output of a logistic regression model, σ(wTx), where σ is the logistic sigmoid function. If you use addition, multiplication, and logistic sigmoid as elements of your computer language, then this model has a depth of 3; if you consider logistic regression as the element itself, then this model has a depth of 1.
The other is the method used in the depth probability model, which does not regard the depth of the calculation graph as the model depth but the depth of the graph describing how the concepts relate to each other as the model depth. In this case, the depth of the calculation flow chart for calculating each concept representation may be deeper than that of the concept itself. This is because the system's understanding of simpler concepts can be refined after giving more complex concepts. For example, when an AI system looks at the face image of one of the eyes in the shadow, it may initially see only one eye. But when the presence of a face is detected, the system can infer that the second eye may also be present. In this case, the conceptual map consists of only two layers (the layer about the eye and the layer about the face), but if we refine the estimate of each concept will require an additional n calculations, the calculated map will contain 2n Floor.
Since it is not always clear which of the depth of the graph is calculated and the depth of the probability model map is most meaningful, and because different people choose different minimum element sets to construct the corresponding graph, it is as if the length of the computer program does not exist. As with a single correct value, there is no single correct value for the depth of the architecture. In addition, there is no deep model to be modified into a "deep" consensus. However, compared to traditional machine learning, the model of deep learning studies involves more combinations of learning functions or concepts, which is beyond doubt.
In short, deep learning is one of the ways to artificial intelligence. Specifically, it is a type of machine learning, a technique that enables computer systems to improve from experience and data. We firmly believe that machine learning can build AI systems that run in complex real-world environments and is the only practical method. Deep learning is a specific type of machine learning. It has powerful capabilities and flexibility. It represents the large-scale world as a nested hierarchical concept system (complex concepts are defined by the links between simpler concepts, general abstractions and high-level abstractions. Indicated). Figure 4 illustrates the relationship between these different AI disciplines. Figure 5 shows the high-level principles of how each discipline works.
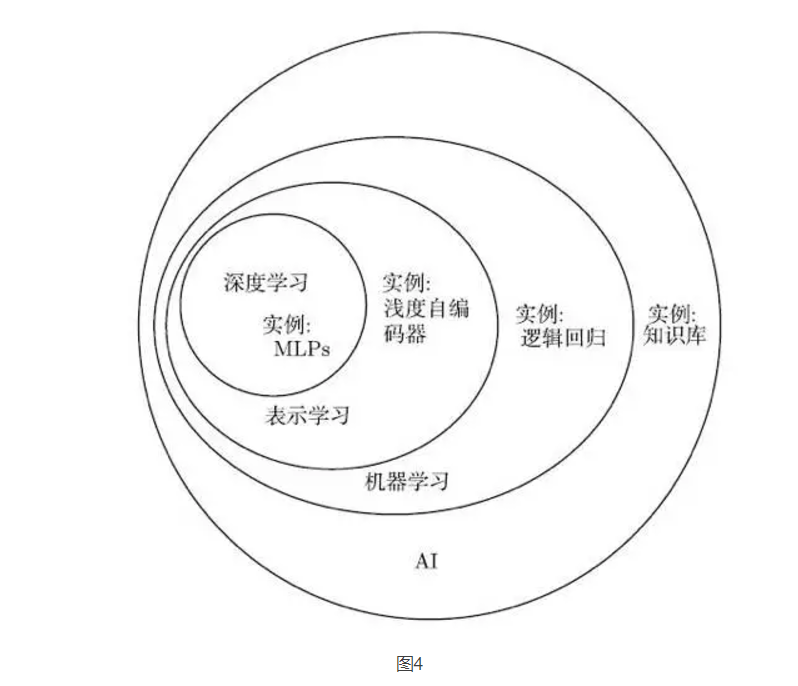
Figure 4 The Venn diagram shows that deep learning is both a representational learning and a machine learning that can be used for many (but not all) AI methods. Each part of the Venn diagram includes an instance of AI technology.
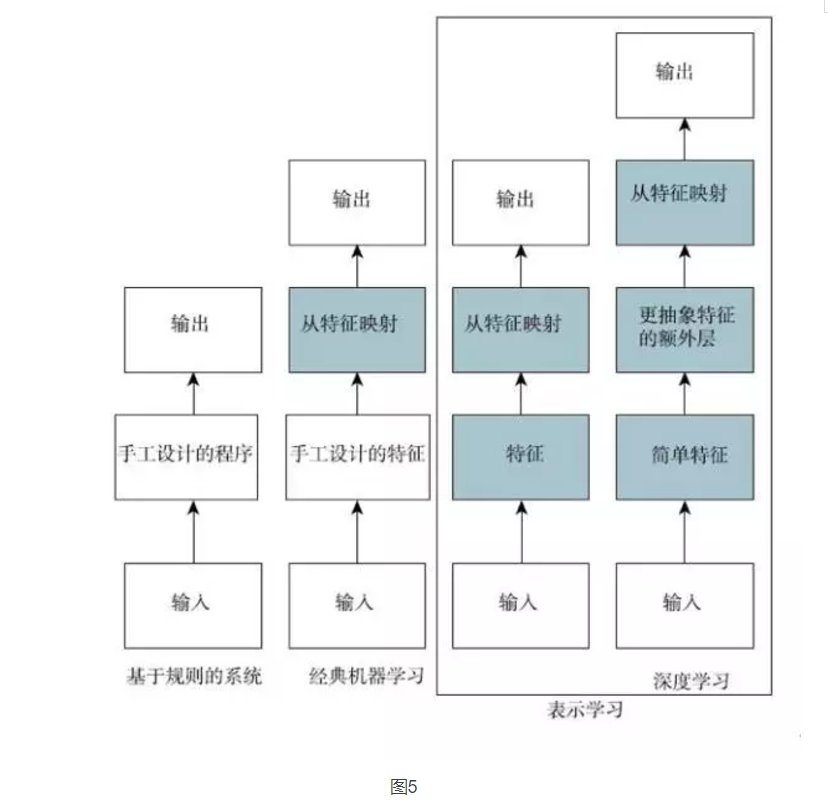
Figure 5 shows how the different parts of the AI ​​system relate to each other in different AI disciplines. Shaded boxes indicate components that can be learned from data.
(This article is taken from "deep learning"
Netease Intelligence opens the "Deep Learning" Chinese version of the donation activity today, and posts messages under WeChat (micro-signal smartman163) and Weibo (Netease Intelligence) about the contents of the "Deep Learning" book. Those who have the highest number of comments will receive a free gift. Book.
DADNCELL alkaline zinc-manganese dry battery has the characteristics of low self-discharge, which is suitable for household batch procurement storage, and has the discharge performance of continuous discharge time with more long-lasting and large instantaneous discharge. Widely used in flashlights, smart door locks, infrared thermometers, cameras, flash lights, razors, electric toys, instruments, high-power remote control, Bluetooth wireless mouse keyboards and other common household electronic equipment instruments. DADNCELL battery advocates providing a more comfortable and smooth power supply experience for household appliances. The alkaline battery capacity and discharge time of the same model of DADNCELL battery have reached four to seven times that of ordinary batteries, respectively.
The performance difference between the two is greater at high and low temperatures, because its unique internal components are structure and battery materials with better performance, and the power capacity and electrical performance can be improved.
At present, all types of batteries developed by DADNCELL Lab do not involve any heavy metals in production, use and waste. They are green and environmentally friendly and can be treated with domestic waste.
1.5V Am-1 Alkaline Cells,All-Purpose Alkaline Batteries,Premium Alkaline D Cell Batteries,Batteries Camera Meters
Shandong Huachuang Times Optoelectronics Technology Co., Ltd. , https://www.dadncell.com